Given a musical sound 
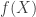





Yet, in the meantime you may have heard of the consonance quality of the perfect fifth interval, e.g. when you play the notes 






so the actual ratio is not 

Given a musical sound
Yet, in the meantime you may have heard of the consonance quality of the perfect fifth interval, e.g. when you play the notes
so the actual ratio is not
Given a Riemannian manifold 






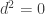



In the physical setting, we may have a vector field 






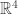
If 







And despite the absurdity in the question, I like the surprise in the answer: Yes. There is a generalized notion of the trace map defined for tensors. Note that we have 



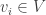





where 

The similarity of the last formula with that of primary trace is noticeable. It’s like that in the original trace definition, the indices are expanding in one dimension (the index was 







It seems that exterior algebra is a more convenient framework for working with the combinatorial attributes of a matrix, since the alternativity properties needed to define those attributes are already built into wedge products. Let me just mention one other example. The Pfaffian 


but if we let 
A point 





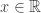


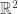




Question: Is there any point in 


